Do you love markdown and LaTeX and native macOS, iPad, and iPhone apps?! Well do I have an exciting app for you! Check out MathDown on the App Store.
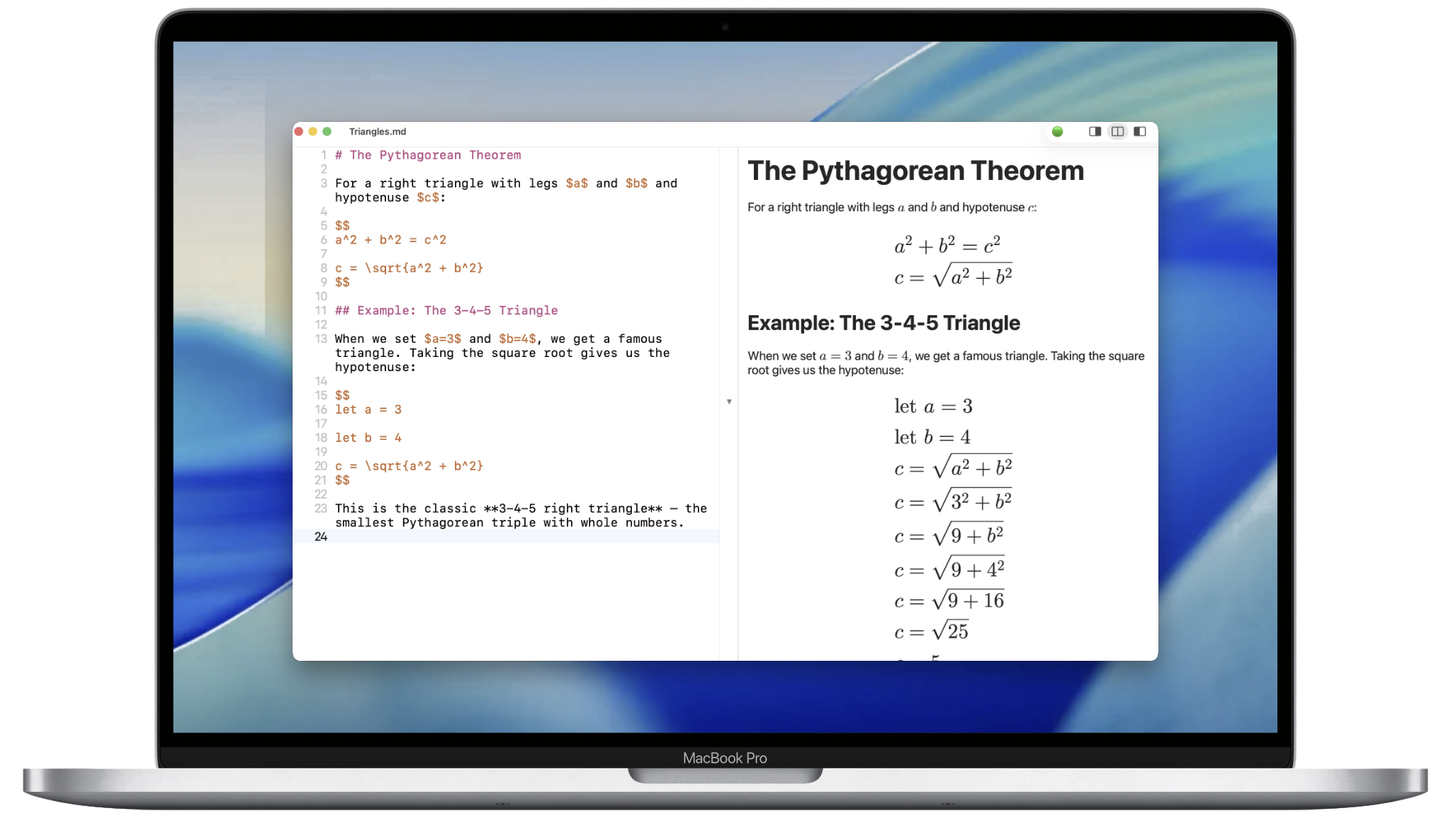
Long ago, I was learning about how machine learner worked under the hood, and I was writing a short book about what I was learning. After all, the best way to learn is to teach!
I wrote in markdown, and used inline LaTeX for the math. At the time, I was using MacDown, a great lightweight editor for macOS. Since then, I’ve also started using Typora, another fantastic and lightweight macOS markdown editor. Both supported LaTeX, so checkmark there, however both are macOS only and don’t support iPad or iPhone.
What’s more, as I was learning about neurons, bias bits, activation functions, and more as part of my machine learning adventure, I found myself wanting a LaTeX editor that could also evaluate the expressions I was typing. I wanted both beautiful typeset math, but I also wanted it to be a LaTeX calculator.
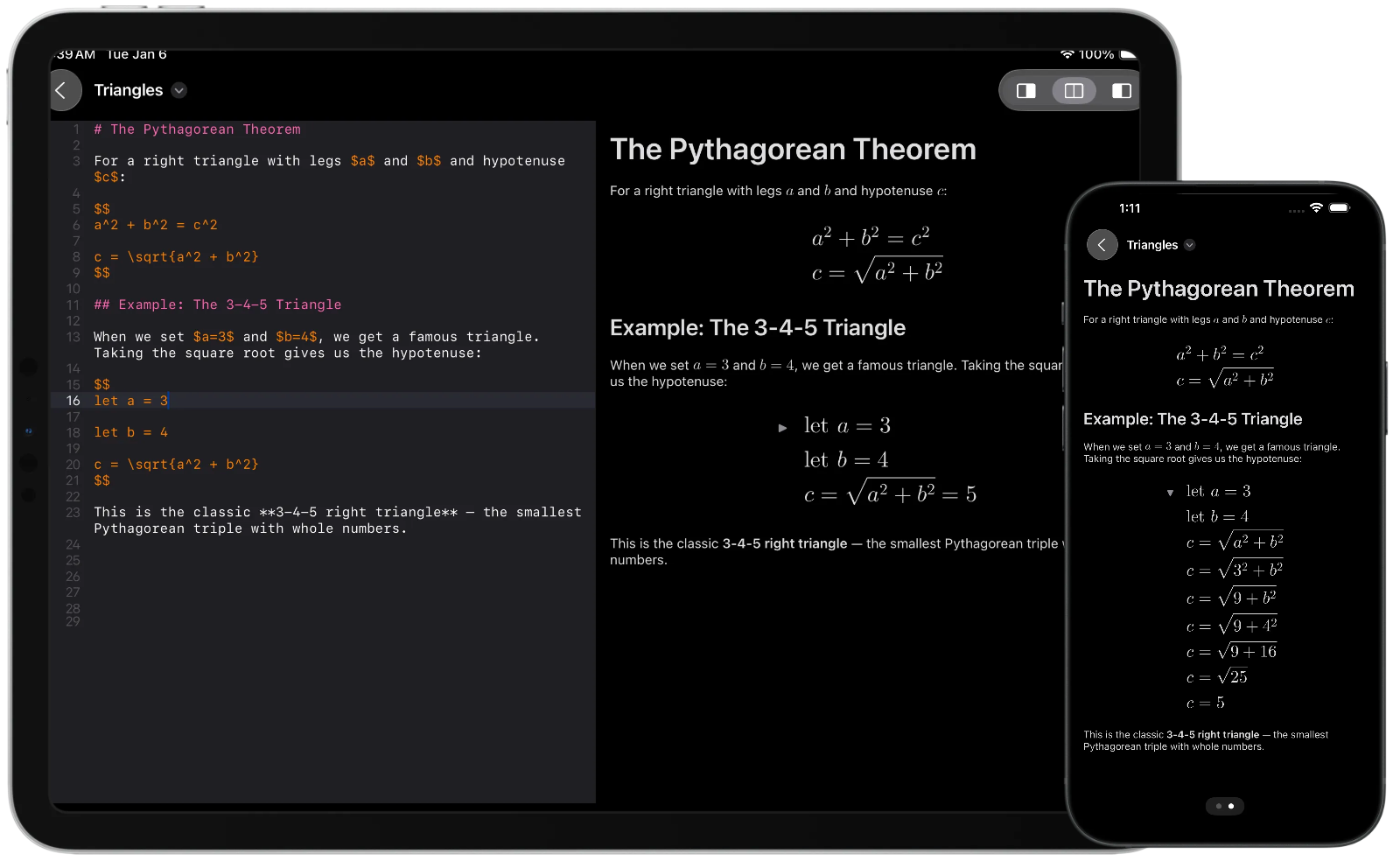
And that’s how MathDown was born: a native macOS, iPad, and iPhone markdown editor with LaTeX support, including the ability to evaluate LaTeX expressions.
MacDown and Typora also both render markdown using HTML and Mathjax, which generally works reasonably well. However, in my brief open source work with MacDown, the constant full-page re-rendering of markdown -> HTML was an annoying bottleneck and was the cause of some annoying UI glitches. I’d found iosMath, and more recently SwiftMath, its Swift port, and was interested in fully native rendering.
The last inspiration I’ll mention is really my first inspiration. I have a computer science degree, and one of my favorite classes during my undergrad was a Computer Language Design course, where we built a language, parsed it into an abstract syntax tree, and built type checkers and interpreters. This was a perfect chance to do exactly that with a LaTeX interpreter.